
After reading another great book from Manning – Redis in Action, authored by Dr. Josiah L Carlson (whom you may know from the “Redis DB” mailing list on Google), i thought you may be interested in key takeaways.
Key facts:
- NoSQL database (key/value store)
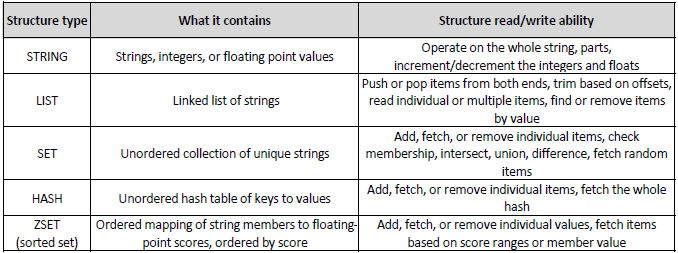
- Stores a mapping of keys to five different types of values (strings, lists, sets, hashes, sorted sets)
- Supports in-memory and and disk persistence
- Supports master/slave replication to scale read performance
- Support for client-side sharding to scale write performance
- Publish/Subscribe capabilities
- Support for scripting (equivalent of stored procedures)
- Partial transaction support
- Support of bulk operations
+ “Sharding is a method by which you partition your data into different pieces. In this case, you partition your data based on IDs embedded in the keys, based on the hash of keys, or some combination of the two. Through partitioning your data, you can store and fetch the data from multiple machines, which can allow a linear scaling in performance for certain problem domains.”
What happens when my server gets turned off?
- Redis has two different forms of persistence available for writing in-memory data to disk in a compact format
- point-in-time dump, either:
- when certain conditions are met (a number of writes in a given period), or
- when one of the two dump-to-disk commands is called.
- append-only file that writes every command that alters data in Redis to disk as it happens. Depending on how careful you want to be with your data, append-only writing can be configured to:
- never sync,
- sync once per second, or
- sync at the completion of every operation
- point-in-time dump, either:
Master/slave replication:
- A good failover scenario if the server that Redis is running on crashes
- Slaves connect to the master and receive an initial copy of the full database.
- As writes are performed on the master, they’re sent to all connected slaves for updating the slave datasets in real time.
- With continuously updated data on the slaves, clients can then connect to any slave for reads instead of making requests to the master.
Random writes:
- are always fast, because data is always in memory,
- queries to Redis don’t need to go through a typical query parser/optimizer
Five data structures available in Redis
Key takeaways:
- Redis is:
- fast – operates on in-memory data sets
- remote – accessible to multiple clients/servers
- persistent – opportunity to keep data on disk
- scalable – via slaving and sharding
Tagged: NoSQL, Redis, Scalability


