
In my previous post on Redis data sharding i introduced the concept of data sharding/partitioning and provided a small Java code example to illustrate the idea. As you noticed i was creating fixed-size “emailbuckets”, containing 1024 emails each. An email address was the key of my hash, while user id was the value. For a shard identifier i used a simple integer value (shardKey) obtained as a result of “i mod shardSize” operation.
Whereas such approach illustrates the concept well, it’s impractical in “real life” applications. This is due to a simple reason – knowing the email address alone (which may often be the only thing you’d know at some point of the app execution flow; for example when you’re using Spring Security and requesting emails “as usernames” during sign-in process), you wouldn’t be able to retrieve the corresponding userId. If you would know the algorithm by which shardKey was generated, in this case – yes – you would be able to traverse emailbuckets one-by-one looking for the appropriate email, but without that knowledge you wouldn’t be able to tell which shard the email address you’re looking for, ended up in.
One solution to that problem is to use a different key for sharding data; something that is computed directly based on the data you’re interested in partitioning. An obvious candidate here is the email address itself. If you’d be able to generate shardKey based on email address you could reproduce the same scenario every time a user provides you with his email during signing in and retrieve his userId (which you could use later on (for example) to further query another hash in Redis – “users:id” – that stores complete user profile).
This seems like an ideal task for a hash function… Let’s start first with some background on hashing. According to Neil Coffey’s Javamex article Introduction to hashing:
- Hashing means using some function or algorithm to map object data (eg. content of a String object) to some representative integer value. This so-called hash code (or simply hash) can then be used as a way to narrow down our search when looking for the item…
Also, when you search Wikipedia after Java hashCode() function, you’ll get the following definition:
- In the Java programming language, every class must provide a hashCode() method which digests the data stored in an instance of the class into a single hash value (a 32-bit signed integer). This hash is used by other code when storing or manipulating the instance – the values are intended to be evenly distributed for varied inputs in order to use in clustering. This property is important to the performance of hash tables and other data structures that store objects in groups (“buckets”) based on their computed hash values.
Looks like this is exactly what we’re interested in – …evenly distributed values for varied inputs…, which …is important to the performance of data structures that store objects in groups (shards in our case) based on their computed hash values.
Conclusion: Java hashCode() function is what we’ll proceed with.
More from Wikipedia on Java hashCode():
- Starting with Java version 1.2, the java.lang.String class implements its hashCode() using a product sum algorithm over the entire text of the string.
- An instance s of the java.lang.String class, would have a hash code h(s) defined by:

- where terms are summed using Java 32-bit int addition, s[i] denotes the i-th character of the string, and n is the length of s.
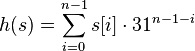
Now, looking at Java docs on String.hashCode() function we can read:
- The hash code for a String object is computed as
s[0]*31^(n-1) + s[1]*31^(n-2) + … + s[n-1] - using int arithmetic, where s[i] is the ith character of the string, n is the length of the string, and ^ indicates exponentiation. (The hash value of the empty string is zero.)
Finally let’s take a look at some Java code of String object showing how hashCode() has actually been implemented:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
An alternative (faster) implementation may look like this (from Apache Harmony JDK):
public int hashCode() {
if (hashCode == 0) {
int hash = 0, multiplier = 1;
for (int i = offset + count - 1; i >= offset; i--) {
hash += value[i] * multiplier;
int shifted = multiplier << 5;
multiplier = shifted - multiplier;
}
hashCode = hash;
}
return hashCode;
}
what’s the difference between the two above code snippets? As you can see, multiplication can be replaced by a bitwise shift operation and a subtraction for better performance. “(multiplier << 5) – multiplier” is just 31*multiplier after all (however VMs nowadays do this optimization automatically). If you’re interested in good reading on the subject of Binary numbers i strongly recommend Neil Coffey’s Javamex article: Introduction to binary numbers.
OK, applying all this knowledge to our sharding code example results in the following implementation:
while(i<1000000) {
String userId = String.valueOf(i++);
String emailAddress = String.format("user_%s@mariuszprzydatek.com", userId);
int shardKey = emailAddress.hashCode();
redisTemplate.opsForHash().put(String.format("emailsbucket:%s", shardKey), emailAddress, userId);
}
Happy coding! 🙂
Resources:
- Redis data sharding – part 1 (https://mariuszprzydatek.com/2013/08/12/redis-data-sharding-part-1)
- Redis performance basics (https://mariuszprzydatek.com/2013/08/07/redis-performance-basics)
- Redis introduction (https://mariuszprzydatek.com/2013/08/05/redis-introduction)
- Introduction to hashing (http://www.javamex.com/tutorials/collections/hashing_intro.shtml)
- Java hashCode() (http://en.wikipedia.org/wiki/Java_hashCode())
- Java docs on String.hashCode() function (http://docs.oracle.com/javase/6/docs/api/java/lang/String.html#hashCode())
- Bitwise operations (http://en.wikipedia.org/wiki/Bitwise_operation)
- Introduction to binary numbers (http://www.javamex.com/tutorials/arithmetic/binary.shtml)
Tagged: Java, NoSQL, Redis, Scalability, Spring Data


